님, 안녕하세요!
AI 트렌드 Bold Flick의 일흔 다섯번째 소식이에요!
이번 주 Bold Flick은 현실 같은 영상을 만들어내는 OpenAI의 Sora 2부터, 아이디어를 시각적으로 ‘섞어내는’ 구글 Mixboard, 그리고 대화하듯 이미지를 완성하는 구글 PASTA까지 한데 모았어요. 영화 속 장면처럼 내 얼굴이 들어가고 떠오른 생각이 바로 비주얼로 변하며 AI와 대화를 나누며 작품이 만들어지는 시대 — 이제 상상이 창작이 되는 속도가 점점 더 빨라지고 있습니다. 이번 호는 한숨 돌리며 “AI가 어디까지 왔나” 감탄할 만한 이야기로 채워졌어요.
|
|
|
#OpenAI #Sora2 #소라2 #Cameos #영상생성
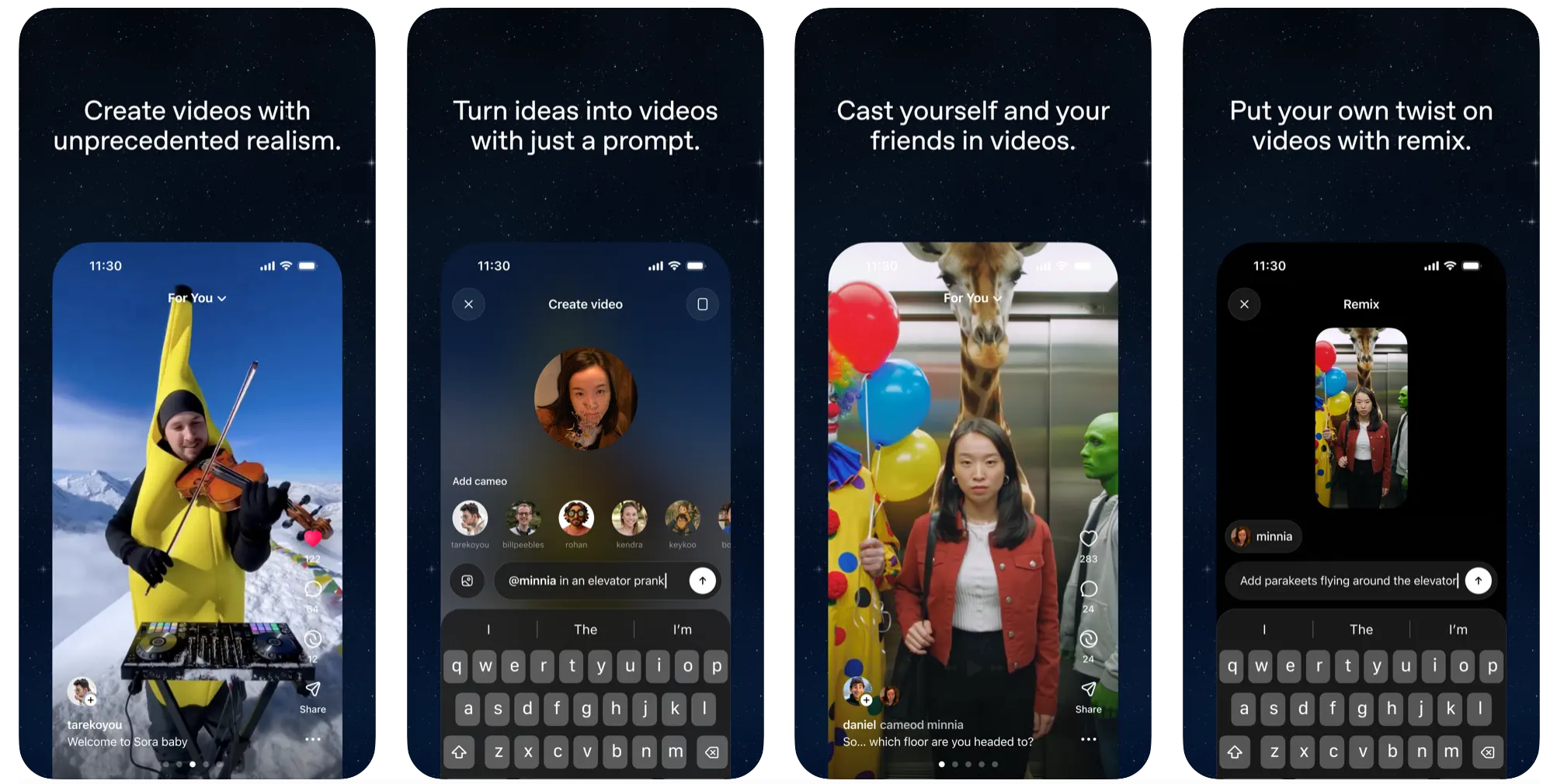
OpenAI, 'Sora 2' 공개!
현실같은 영상에 내 얼굴(Cameo)까지!
|
|
|
<물리적 정확성, 오디오 동기화, 그리고 틱톡 닮은 소셜 플랫폼까지> by.VQZ
|
|
|
OpenAI가 드디어 플래그십 동영상 및 오디오 생성 모델 'Sora 2'를 공개했습니다! 이는 지난 2월의 오리지널 Sora를 뛰어넘어 GPT-3.5 모멘트에 비견될 만큼 혁신적인 진전을 이룬 것으로 평가돼요. 특히 현실과 가까운 물리적 정확성, 그리고 사용자의 '카메오(Cameos)' 기능을 중심으로 한 새로운 소셜 앱 출시가 핵심이랍니다.
Sora 2는 이전 모델이 해결하지 못했던 난제들을 극복했어요. 이전 모델이 농구 선수가 슛을 놓쳤을 때 공이 저절로 골대에 들어가는 것처럼 물리 법칙을 무시하는 경향을 보였다면, Sora 2에서는 농구공이 백보드에 맞고 튕겨 나오는 등 물리학 법칙을 더 잘 따릅니다. 복잡한 장면의 동역학도 정확하게 모델링하며, 오디오 사운드스케이프, 대화, 효과음까지 영상과 완벽히 동기화하여 생성해낼 수 있게 되었죠.
가장 눈에 띄는 것은 '카메오(Cameos)' 기능을 내세운 새로운 Sora 소셜 앱(iOS) 출시입니다. 이 앱은 틱톡(TikTok)과 유사한 세로형 피드를 갖추고 있지만, 모든 콘텐츠가 AI로 생성된다는 점이 차이점이에요. 사용자는 짧은 본인 인증 과정을 거쳐 자신의 얼굴과 목소리를 AI 생성 영상 속에 정확히 삽입할 수 있어요. 이는 텍스트나 이모지를 넘어선 새로운 형태의 커뮤니케이션으로 자리 잡을 것으로 기대됩니다. 현재 이 앱은 미국과 캐나다에서 무료(제한된 사용량)로 출시되었고, ChatGPT Pro 사용자에게는 'Sora 2 Pro' 모델 접근 권한이 제공돼요. |
|
|
Sora 2는 AI가 물리적 세계를 시뮬레이션하는 데 한 걸음 더 다가섰음을 의미합니다. 또한, OpenAI는 소셜 앱을 설계하며 '사용자 웰빙'을 최우선 목표로 삼았다고 밝혔어요. "소비가 아닌 창작을 최대화"하도록 설계되었고, 부모를 위한 '자녀 보호 기능(Parental Controls)'이나 유해 콘텐츠 방지책도 함께 마련했죠. 한편으로는 할리우드 스튜디오 등 저작권자를 위한 IP 제외 요청(opt-out) 기능도 도입할 예정이라, 앞으로 콘텐츠 시장에서 AI와 저작권의 공존이 어떻게 이루어질지 주목됩니다.
현실과 AI 창작의 경계가 무너지는 순간이 바로 지금인 것 같습니다! 나의 얼굴과 목소리를 영화 같은 AI 영상에 넣어 친구들과 공유하는 기능, 여러분은 이 '카메오' 기능으로 어떤 기발한 영상을 만들어보고 싶으신가요? |
|
|
#구글 #Mixboard #믹스보드 #AI무드보드 #google
구글 믹스보드 공개!
AI가 아이디어를 '섞어서' 무드보드로 짠!
|
|
|
<텍스트, 이미지, AI가 만나 창의적인 구상을 현실로 만드는 새로운 방법> by.VQZ
|
|
|
구글이 창의적인 아이디어를 시각적으로 구상할 수 있는 새로운 AI 도구, '믹스보드(Mixboard)'를 공개했습니다! 디지털 무드보드처럼 텍스트와 이미지를 자유롭게 조합하는 AI 기반 플랫폼이죠. 현재 미국에서 공개 베타 버전으로 제공되며 큰 관심을 받고 있어요.
믹스보드는 사용자의 아이디에이션(Ideation)과 브레인스토밍을 위해 설계되었습니다. 이 도구의 핵심은 여러 이미지를 배치하고, AI의 도움을 받아 흥미로운 방식으로 조합하는 능력이에요. 특히 구글의 이미지 편집 모델인 '나노 바나나(Nano Banana)' AI가 통합되어 있어, 자연어 명령만으로 이미지 생성과 편집을 한 번에 처리할 수 있답니다. 단순 이미지 수집을 넘어, AI가 새로운 비주얼 콘텐츠를 생성하는 데 초점을 맞추고 있어요.
|
|
|
믹스보드의 가장 강력한 기능은 바로 '이미지 혼합(Image Mixing)'입니다. 보드 위의 공작새와 붉은 새 이미지를 선택한 후 "이 두 이미지를 혼합"하라고 입력하면, AI가 합쳐진 새로운 이미지를 빠르게 생성해줍니다. 사용자들은 이 기능을 활용해 홈 데코, 이벤트 테마, DIY 프로젝트 등 다양한 결과물을 얻을 수 있죠. 예를 들어 "멤피스 스타일의 컵, 그릇, 접시"라고 입력하면 관련 이미지를 즉시 생성하고, 유사한 디자인으로 '재생성(Regenerate)'하는 것도 가능해요.
믹스보드는 기존 디자인 툴과 유사하면서도 생성형 AI를 핵심 기능으로 내세운 점에서 차별화됩니다. 전문적인 디자인 기술 없이도 누구나 자연어 명령만으로 아이디어를 시각화하고 발전시킬 수 있다는 의미예요. 앞으로 디자이너와 일반 사용자 모두에게 혁신적인 워크플로우를 제공할 것으로 기대됩니다.
텍스트와 이미지, 아이디어까지 섞어서 새로운 무언가를 만들어낸다니 정말 매력적이죠? 복잡한 툴 없이도 머릿속 영감을 바로 시각화할 수 있는 시대가 성큼 다가왔습니다. 여러분은 이 '혼합 기능'으로 어떤 참신한 아이디어를 구상해보고 싶으신가요?
|
|
|
#AI #Google #PASTA #이미지AI #협업형생성 #연구발표
구글 대화하듯 이미지를 만드는 AI ‘PASTA’ 공개
|
|
|
<사용자 피드백에 따라 스스로 발전하는 이미지 생성 모델> by.D-Caf
|
|
|
“이건 아닌데…” 이미지 생성기를 써보다가 고개를 갸웃해본 적 있으시죠? 구글 리서치 팀이 이런 문제를 해결하기 위해 새로운 접근 방식을 내놨어요. 이름도 귀엽게 PASTA(Preference Adaptive and Sequential Text-to-Image Agent) 라고 합니다. 이번 모델은 사용자의 말을 한 번에 완벽히 이해하려 하기보다 대화를 이어가며 점점 더 나은 이미지를 만들어가는 협업형 AI예요. |
|
|
PASTA는 기존처럼 프롬프트 한 줄로 이미지를 바로 완성하지 않습니다. 사용자가 “조금 더 밝게”, “배경은 바다로 바꿔줘” 같은 피드백을 주면 AI가 그걸 반영해 새 이미지를 제안하죠. 이 과정을 여러 번 반복하면서 사용자의 취향을 학습하고 결과물을 스스로 개선해 나갑니다.
구글은 이를 위해 7,000명 이상의 사용자 피드백 데이터를 활용해 다양한 성향의 ‘사용자 타입’을 모델에 반영했다고 해요. 또 텍스트와 이미지를 연결하는 CLIP 인코더 프롬프트 확장을 돕는 Gemini Flash까지 결합해 실제 대화하듯 자연스러운 수정이 가능하도록 만들었습니다. |
|
|
실험 결과, PASTA는 기존 Stable Diffusion XL 기반 모델보다 사용자 만족도와 결과물 품질 모두 크게 향상된 것으로 나타났어요. 단순히 AI에게 명령하는 시대에서 벗어나 AI와 함께 결과물을 만들어가는 방식으로 한 단계 진화한 셈이죠. |
|
|
PASTA는 “어떻게 시키느냐”보다 “어떻게 같이 만들어가느냐”에 초점을 맞춘 모델이에요. 이제는 프롬프트 대신 대화로 AI와 진짜 협업이 시작된 거죠! |
|
|
오늘의 'Bold Flick'은 여기까지!
다음 뉴스레터에서는 더욱 놀랍고 흥미로운 AI 소식으로 찾아뵐게요.
언제나 Bold Flick을 사랑해주셔서 감사합니다! 💙
궁금한 점이 있거나 더 알고 싶은 주제가 있다면 언제든 말씀해 주세요.
여러분의 피드백이 저희에게 큰 힘이 된답니다!
|
|
|
|