님, 안녕하세요!
AI 트렌드 Bold Flick의 쉰 아홉 번째 소식이에요!
이번 주도 AI계에선 상상 초월의 기술들이 쏟아졌습니다.
“AI가 물리 법칙을 이해한다”, “장난감이 대화한다”, “한 줄로 영상 찍는다”...
이거 진짜 현실 맞나요?
이번 회차에선 Meta의 '세계 모델', Mattel의 AI 장난감, ByteDance의 씬 단위 영상 생성 모델까지 놀라운 세 가지 소식을 한데 담았어요.
커피 한 잔과 함께 이번에도 뇌를 톡톡 자극해보세요! 🧠☕
|
|
|
#AI #WorldModel #Meta #VJEPA #RobotPlanning
메타, 물리 추론 가능한 세계 모델 V-JEPA 2 공개
|
|
|
<비디오 기반 직관 학습으로 로봇 제어까지 지원하는 세계 모델> by.VQZ
|
|
|
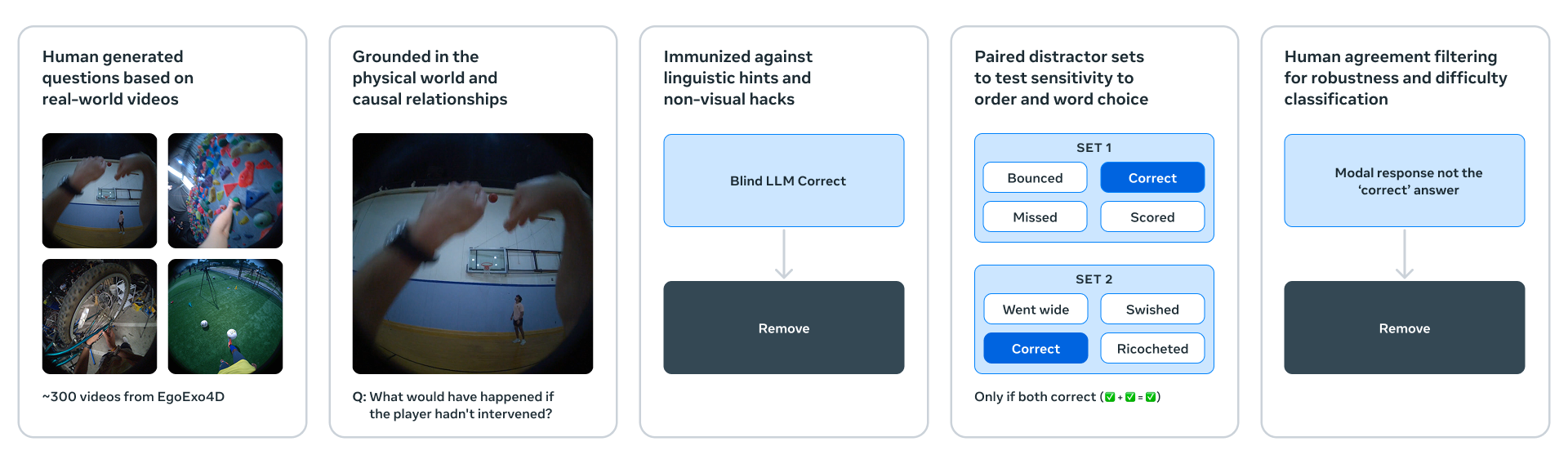
메타(Meta)가 비디오 기반의 세계 모델(world model) 'V-JEPA 2'를 발표했어요. 이 모델은 단순한 비주얼 인식 수준을 넘어서, 실제 물리 세계의 상황을 예측하고 계획하는 능력을 갖췄다고 해요. 예컨대 낯선 물체를 인식하고, 그것을 잡아 다른 위치에 놓는 등의 로봇 행동도 가능하다고 하죠.
V-JEPA 2는 12억 파라미터 규모로, 영상 데이터를 중심으로 훈련되었고 인간의 직관처럼 사전 경험 없이도 상황을 예측하거나 조작 가능성을 판단할 수 있어요. 기존에는 이미지 기반 모델이 주류였지만, 이번엔 비디오 기반 학습을 통해 시간 흐름 속에서 객체가 어떻게 움직이는지를 이해하고, 그에 따라 행동을 계획할 수 있는 구조를 갖췄습니다.
훈련은 두 단계로 이뤄졌어요. 첫 번째는 100만 시간 분량의 영상과 이미지를 활용한 사전 훈련(pre-training), 두 번째는 로봇 제어 데이터 기반의 행동 조건 훈련입니다. 이 과정을 통해 모델은 예측 기반의 플래닝 능력을 획득했고, 특정 로봇의 데이터가 없어도 새로운 환경에서 제로샷(Zero-shot) 방식으로 작동할 수 있어요. 특히 로봇이 현재 상태에서 목표 이미지까지 어떤 경로로 도달해야 할지를 스스로 계획해내는 방식이 흥미롭습니다. |
|
|
메타는 이번에 함께 3개의 새로운 벤치마크도 공개했어요. IntPhys 2는 물리 법칙 위배 여부를 구분하는 테스트이고, MVPBench는 사소한 영상 차이에도 정답을 맞추도록 구성된 최소 변화 문제쌍 테스트예요. 마지막 CausalVQA는 인과 추론과 계획 능력을 평가하는 비디오 기반 QA입니다.
이번 발표는 메타가 추진 중인 '고도화된 기계 지능(Advanced Machine Intelligence)'의 핵심 축인 세계 모델 개발이 한층 현실화되고 있음을 보여줘요. AI가 물리 세계에서 직접 작동하고 계획할 수 있는 기반이 점차 마련되는 중입니다. |
|
|
#Mattel #OpenAI #AI장난감 #BarbieAI #ChatGPT엔터프라이즈 #디지털플레이
매텔, 오픈AI와 손잡고 AI 장난감 개발
|
|
|
<Barbie와 Hot Wheels에도 AI 경험이 탑재될까?> by.VQZ
|
|
|
세계적인 완구 기업 매텔(Mattel)이 오픈AI(OpenAI)와 전략적 협업을 체결했어요. 이번 파트너십은 매텔의 대표 브랜드에 AI를 접목한 ‘지능형 장난감’과 디지털 경험을 제공하는 것을 목표로 하며, 올해 말 첫 제품 출시가 예정돼 있어요.
이번 협업을 통해 매텔은 오픈AI의 ChatGPT 기술을 포함한 다양한 생성형 AI 도구를 제품과 서비스 개발에 통합할 예정이에요. 특히 Barbie, Hot Wheels, American Girl 같은 아이콘 브랜드를 중심으로, AI를 활용한 맞춤형 인터랙션과 놀이 경험이 구현될 전망이에요. 또한, 매텔 내부에서는 ChatGPT 엔터프라이즈를 도입해 창의적 아이디어 발굴 및 업무 자동화를 꾀하고 있어요.
|
|
|
안전성과 연령 적합성은 협업의 핵심 가치로 강조되고 있으며, 매텔은 최종 제품에 대한 통제권을 유지하면서 오픈AI의 기술력을 적극 활용할 방침이에요. 오픈AI의 COO 브래드 라이트캡은 “이번 협업을 통해 창의성과 생산성을 극대화할 새로운 도구를 제공하게 될 것”이라고 전했어요.
장난감과 AI의 융합은 그 자체로 큰 의미를 갖지만, 일부에서는 어린이 대상 AI 상호작용의 윤리성과 프라이버시 이슈도 제기되고 있어요. 하지만 매텔은 오랜 시간 동안 쌓아온 신뢰를 바탕으로, 책임 있는 기술 도입에 무게를 두고 있어요.
AI 기술이 단순한 대화형 챗봇을 넘어 장난감 속으로 들어오는 시대, Mattel x OpenAI는 그 첫 사례가 될지도 몰라요.
|
|
|
#AI #Seedance1.0 #ByteDance #AI영상 #멀티샷영상
ByteDance 영상도 씬 단위로 찍는 시대 열었다
|
|
|
<Seedance 1.0 Pro 공개… “텍스트로 영화 한 장면 찍기” 가능해져> by.D-Caf
|
|
|
틱톡 만든 그 회사 ByteDance, 이번엔 AI 영상 생성 모델로 또 한 번 판을 흔들었어요. 이름은 바로 Seedance 1.0 Pro. 그냥 텍스트 하나만 던지면 10초짜리 1080p 고화질 영상이 샷 단위로 뚝딱 만들어져요. 한 마디로 “고양이가 우주선 타고 떠나요” 이러면, 장면이 A → B → C 이렇게 영화처럼 흐름 있게 뽑히는 거죠! |
|
|
Seedance 1.0 Pro의 가장 큰 특징은 단순히 영상 하나를 ‘툭’ 만들어주는 게 아니라서사 구조가 있는 장면 흐름을 구성해준다는 점이에요. 기존의 많은 AI 영상 생성 도구들이 한 컷의 이미지를 움직이게 하는 데 그쳤다면 Seedance는 그 한계를 넘어선 셈이죠. |
|
|
기술적으로도 꽤 인상적입니다. 텍스트 기반 생성(T2V)뿐만 아니라 이미지 기반 생성(I2V)까지 함께 학습했고, RLHF 기법을 통해 ‘사람 눈에 보기 좋은 흐름’이 무엇인지도 반영할 수 있도록 훈련됐다고 해요. 여기에 장면별로 컨텍스트를 분리해서 영상의 일관성을 더 높이고 사용자 인터페이스도 직관적으로 구성돼 있어서 영상 생성 결과를 바로 확인하고 수정할 수 있어요. |
|
|
지금은 데모 중심이지만 API나 SaaS 툴도 곧 공개될 예정이라 이거 잘만 쓰면 누구나 “AI 영상 감독” 되는 날이 멀지 않았어요!
이제 텍스트 한 줄이면 영상 한 장면이 뚝딱 Seedance는 그냥 ‘움직이는 그림’이 아니라 “이야기 흐름까지 잡아주는 AI 영상 감독”이 되어주고 있어요
여러분도 다음 장면 Seedance로 찍어보실래요?🎬
|
|
|
오늘의 'Bold Flick'은 여기까지!
다음 뉴스레터에서는 더욱 놀랍고 흥미로운 AI 소식으로 찾아뵐게요.
언제나 Bold Flick을 사랑해주셔서 감사합니다! 💙
궁금한 점이 있거나 더 알고 싶은 주제가 있다면 언제든 말씀해 주세요.
여러분의 피드백이 저희에게 큰 힘이 된답니다!
|
|
|
|