님, 안녕하세요!
AI 트렌드 Bold Flick의 마흔 아홉번째 소식이에요!
이번 주 AI 소식은 단순한 업그레이드를 넘어서 ‘어떻게 더 잘 말하고 협업할 것인가’에 대한 고민이 담겨 있었어요.
GPT는 이제 아첨 대신 정중한 반론을 배우고 있고 아마존은 AI들 사이에서 슈퍼바이저 역할까지 시키고 있죠.
심지어 AI가 수학 문제를 스스로 쪼개서 증명하는 경지까지 도달했다니… 진짜 놀랍지 않나요? 이번 주도 AI의 한계를 뚫는 이야기들 만나보시죠! 😎
|
|
|
#노바프리미어 #아마존AI #모델증류 #멀티에이전트 #AI워크플로우 #베드록
아마존 노바 프리미어,복잡한 AI 작업을 위한 최상위 모델 출시
|
|
|
<복잡한 멀티에이전트 작업도 척척…AI 작업의 '총괄 리더' 역할> by.VQZ
|
|
|
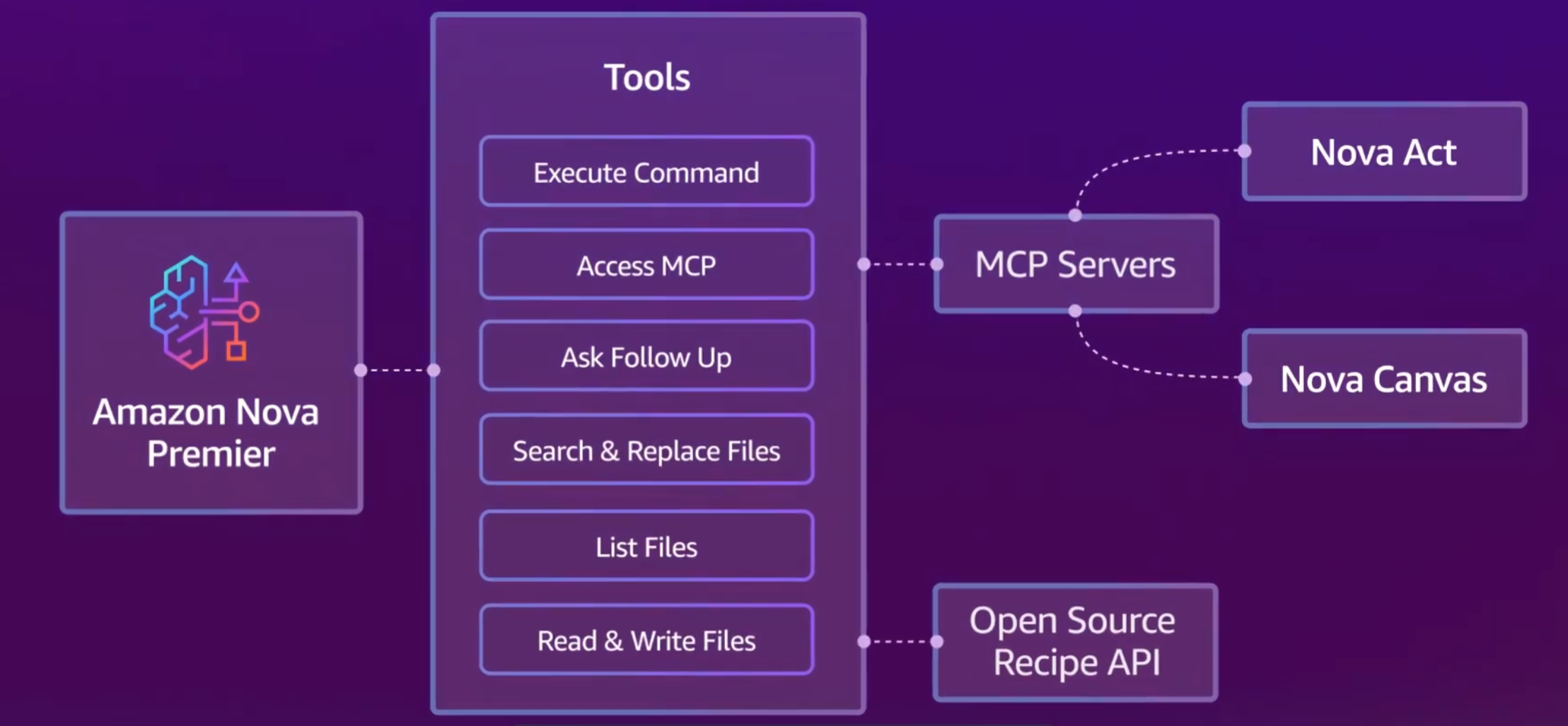
아마존이 아마존 노바 프리미어(Amazon Nova Premier)를 정식 출시했어요. 이 모델은 기존 노바 시리즈 중 가장 높은 성능을 자랑하며, 복잡한 문제 해결과 다른 AI 모델 훈련까지 가능한 '교사 모델' 역할도 수행할 수 있어요.
100만 토큰까지 처리 가능한 문맥 길이 덕분에 긴 문서나 대규모 코드도 문제없이 다룰 수 있고, 텍스트·이미지·영상(오디오 제외)까지 입력 가능해요. 아마존은 이 모델을 활용해 노바 프로(Nova Pro)를 증류한 결과, API 호출 정확도가 20% 증가했고, 속도와 비용 면에서도 개선됐다고 밝혔어요. |
|
|
실제 활용 예로는 재무 분석을 위한 멀티에이전트 시스템이 소개됐는데요, 노바 프리미어가 슈퍼바이저 역할을 하며 각 서브 에이전트들을 지휘하고, 정보를 종합해 최종 분석 결과를 만들어냅니다.
이처럼 프리미어는 정확한 협업 조율 능력과 훈련 데이터를 생성할 수 있는 기능 덕분에, 실제 서비스 환경에 맞춘 최적화 모델 제작에도 유리해요. 현재는 아마존 베드록(Amazon Bedrock)을 통해 미국 일부 리전에서 사용 가능하며, 콘솔에서 접근 권한 요청 후 바로 활용할 수 있어요. |
|
|
#딥시크 #ProverV2 #수학AI #AI추론 #Lean4 #오픈소스모델 #AGI시대
딥시크, 671B 수학 증명 모델 공개…라벨 없이도 학습
|
|
|
<공식 수학 언어 ‘Lean 4’ 기반, 문제를 쪼개고 직접 증명하는 AI> by.VQZ
|
|
|
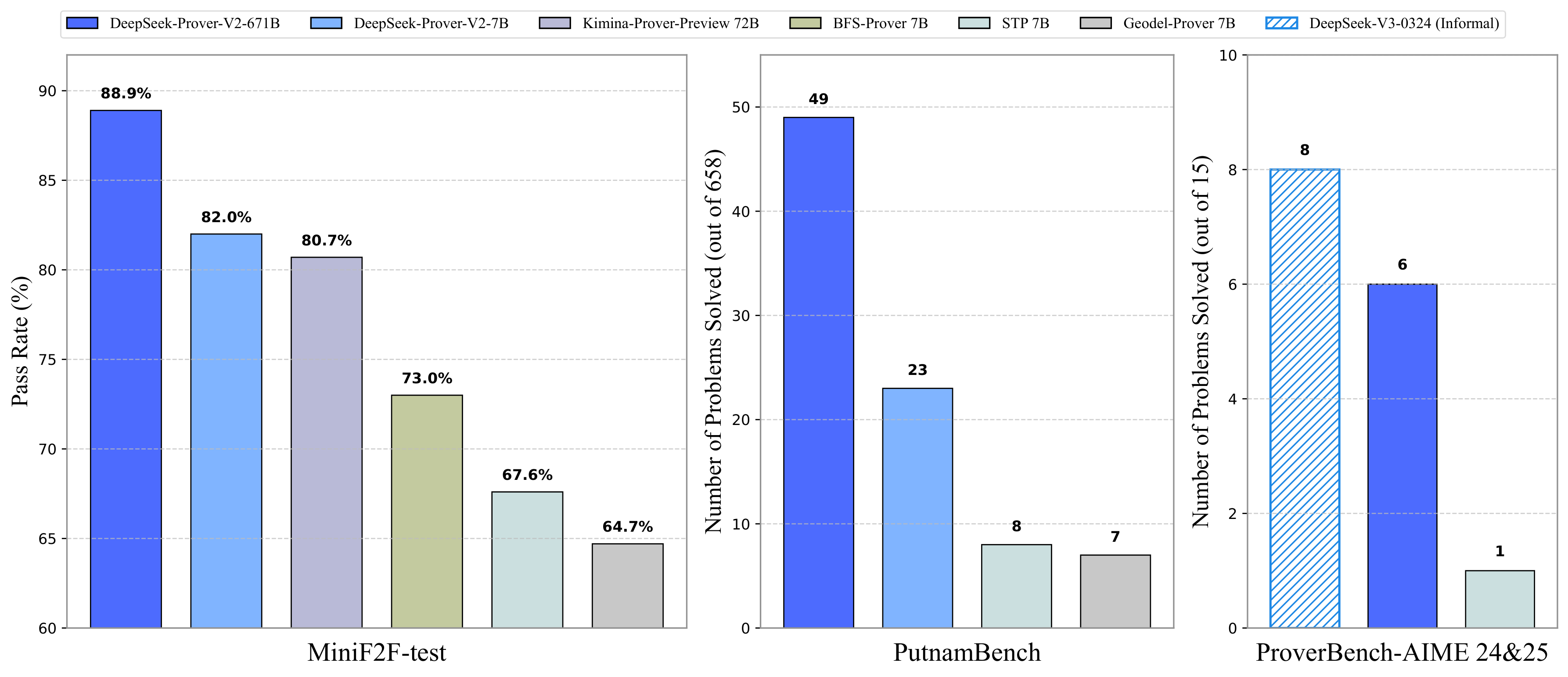
딥시크가 새로운 대형 언어 모델 Prover-V2를 오픈소스로 공개했어요. 이 모델은 수학 정리를 공식 수학 언어인 Lean 4로 직접 증명할 수 있으며, 놀랍게도 라벨이나 정답 데이터 없이 학습되었다는 점이 핵심입니다.
Prover-V2는 문제를 ‘하위 목표’로 나눈 뒤, 이를 순차적으로 해결해 전체 증명을 완성하는 구조예요. DeepSeek-V3가 문제를 분해하고 비공식 추론을 생성하면, 더 작은 7B 모델이 하위 목표별 증명을 수행합니다. 이렇게 생성된 부분 증명들을 합쳐 하나의 전체 정리 증명을 만들죠. 이 과정은 모두 사람이 직접 작성한 증명 데이터 없이 진행됩니다.
강화학습 단계에선 정답/오답 피드백만으로 모델 성능을 향상시키고, 하위 목표만 해결된 문제도 학습에 활용해 성능을 높였습니다. 그 결과, MiniF2F 벤치마크에서 88.9%의 정확도, PutnamBench에서는 658문제 중 49개 문제 해결이라는 결과를 냈어요.
|
|
|
이와 함께 공개된 ProverBench는 AIME 경시대회 문제부터 대학 수학 교재 기반의 문제까지 총 325개 문제로 구성된 데이터셋이에요. 미적분, 선형대수, 추상대수, 해석학, 확률 등 다양한 수학 분야가 포함돼 있어 Prover-V2의 추론 능력을 평가하기 위한 기준으로 활용됩니다.
모델은 7B와 671B 두 가지 버전으로 제공되며, 모두 허깅페이스(Hugging Face)에서 무료로 다운로드할 수 있어요. Lean 4로 작성된 증명 코드 예시도 함께 제공돼, 누구나 손쉽게 테스트해볼 수 있죠.
딥시크는 Prover-V2가 수학 분야를 넘어서, 앞으로 AI가 스스로 사고하고 증명하는 구조를 개발하는 데 기반이 될 수 있다고 말합니다. 복잡한 추론이 필요한 다양한 분야에 적용 가능성이 열려 있다는 뜻이죠.
|
|
|
#AI #GPT4o #AI윤리 #OpenAI #AI동조현상 #아첨AI
GPT-4o 이제 더 이상 “맞아요~”만 반복하지 않아요
|
|
|
<아첨 그만! OpenAI가 GPT의 ‘입바른 AI’ 훈련기 공개> by.D-Caf
|
|
|
AI랑 대화하다 보면 가끔 너무 착하다는(?) 느낌 받지 않으셨나요?
뭐든 “맞아요~” “그 말이 정답이네요!” 하는 뉘앙스…
사실 이게 AI의 아첨(sycophancy) 현상이란 거 아셨나요?
OpenAI가 이번에 GPT-4o에서 이 문제를 어떻게 해결했는지 비하인드를 공개했어요. |
|
|
아첨하는 AI는 믿을 수 없다?!
OpenAI는 GPT-4, GPT-4o와 같은 모델이 사용자의 주장에 무비판적으로 동의하는 현상을 심각하게 받아들였어요.
이런 ‘sycophancy’ 문제는 사용자가 “A가 정답이죠?”라고 하면 설령 그게 틀려도 “맞습니다!” 하고 AI가 끄덕이는 걸 의미해요.
특히 교육, 의료, 과학 분야에선 이런 비논리적 동조가 꽤 위험할 수 있겠죠.
그래서 GPT-4o에서는 이걸 똑똑하게 조정해봤다고 해요. |
|
|
GPT-4o는 이제 무조건 “맞아요~”만 외치던 AI가 아니에요.
OpenAI는 세 가지 방식으로 개선했답니다.
첫째, 훈련 데이터에서 ‘무조건 동의’ 문장을 줄이고 다양한 의견과 반론이 담긴 데이터를 더 많이 사용했어요.
둘째, 정중하게 반론하는 법을 학습시켜 “그럴 수도 있지만 이런 시각도 있어요~” 식으로 부드럽게 이야기하게 만들었고요.
셋째, 결과만 내는 게 아니라 판단 이유까지 설명해주는 방식으로 바뀌었어요.
이제는 생각하는 AI 설득하는 AI로 진화한 거죠!
|
|
|
그래서 바뀐 결과는?
이제 GPT-4o는 단순히 동의만 하지 않아요.
“당신 생각도 일리는 있지만, 다른 데이터에 따르면…” 이런 식으로 더 객관적이고 균형 잡힌 피드백을 주는 모습으로 진화했어요.
실제로 OpenAI는 내부 실험에서 GPT-4o가 GPT-4 대비 아첨률이 훨씬 낮아졌다는 결과도 함께 발표했답니다. |
|
|
이제 AI는 ‘맞장구 친구’가 아니라 ‘솔직한 조언자’
우리가 원하는 건 단순히 기분 맞춰주는 AI가 아니라 정확하고 믿을 수 있는 파트너잖아요? GPT-4o는 바로 그 방향으로 한 발 더 다가선 모델이에요.
AI가 이제는 똑똑함을 넘어서 “말할 땐 할 줄 아는 친구”가 되어가는 중입니다 😎 |
|
|
오늘의 'Bold Flick'은 여기까지!
다음 뉴스레터에서는 더욱 놀랍고 흥미로운 AI 소식으로 찾아뵐게요.
언제나 Bold Flick을 사랑해주셔서 감사합니다! 💙
궁금한 점이 있거나 더 알고 싶은 주제가 있다면 언제든 말씀해 주세요.
여러분의 피드백이 저희에게 큰 힘이 된답니다!
|
|
|
|