2026년 첫 Bold Flick은 시작부터 속도가 다릅니다. 영상 생성 시간을 초 단위로 줄여버린 TurboDiffusion, 가성비와 성능을 동시에 잡은 오픈소스 코딩 모델 GLM-4.7, 그리고 이미지를 레이어 단위로 다루게 만든 Qwen의 새로운 시도까지 담았어요. 작년이 “AI가 가능해진 해”였다면 올해는 분명히 AI가 체감되는 해로 출발하는 느낌입니다.
기다림은 줄고, 선택지는 늘고, 결과는 더 빨라진 지금 2026년의 첫 페이지를 여는 이 변화들이 앞으로 어떤 흐름으로 이어질지 이번 호에서 가볍게 함께 살펴보시죠 ☕️
<분 단위 작업이 단 몇 초 만에? 97배 빨라진 속도 누구나 고품질 영상 만든다.>by.VQZ
ⓒ TurboDiffusion
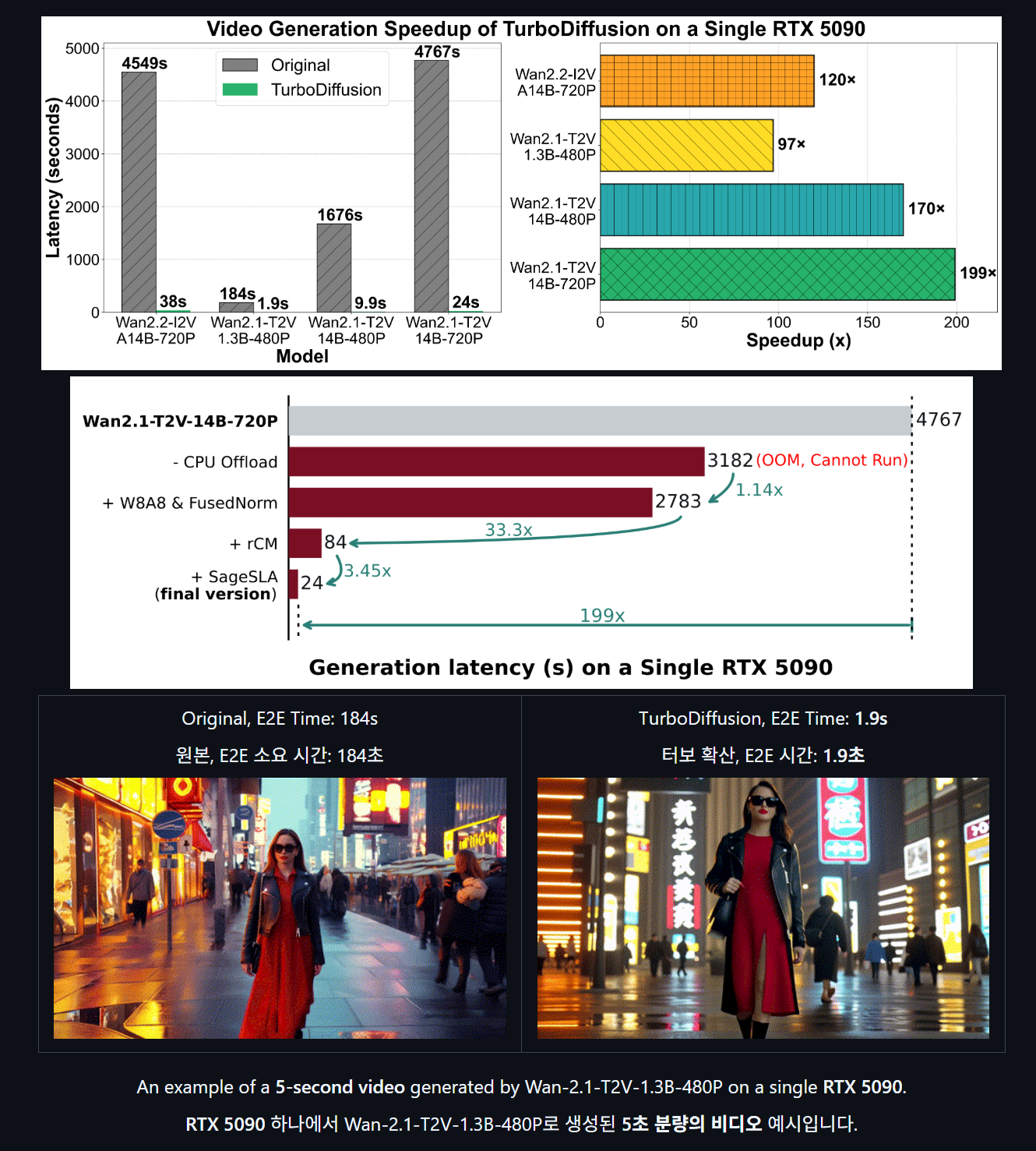
칭화대학교 TSAIL 연구소와 생슈테크(Shengshu Tech)가 협력해 AI 영상 생성 속도를 획기적으로 높여주는 가속 프레임워크, 'TurboDiffusion'을 오픈소스로 공개했습니다! 그동안 고화질 AI 영상을 하나 만들려면 강력한 하드웨어에서도 몇 분씩 기다려야 했는데요. 이제는 단 한 장의 GPU만으로도 이 과정을 단 몇 초 만에 끝낼 수 있게 되었습니다. 영상 제작의 패러다임을 바꿀 진정한 '속도 혁명'이 시작된 셈이죠.
ⓒ TurboDiffusion
성능 수치를 보면 정말 놀랍습니다. 최신 RTX 5090 GPU 기준으로 테스트했을 때, 기존에 약 184초가 걸리던 영상 생성 작업이 단 1.9초 만에 완료되었어요. 무려 97배에서 최대 200배까지 가속된 셈인데, 이는 품질을 희생하지 않으면서도 어텐션 메커니즘 최적화와 양자화 기술을 절묘하게 결합한 덕분입니다. 덕분에 이제 개인 크리에이터들도 전문가 수준의 영상을 실시간에 가깝게 뽑아낼 수 있는 환경이 마련되었습니다.
TurboDiffusion의 핵심 기술인 'SageAttention'은 이미 엔비디아(NVIDIA) 텐서RT에 통합되었고, 텐센트나 바이트댄스 같은 글로벌 빅테크 기업들의 제품에도 도입되었다고 합니다. 이 기술은 광고 마케팅의 실시간 피드백이나 교육용 콘텐츠 제작 등 빠른 속도가 생명인 분야에서 큰 힘을 발휘할 것으로 보여요. 물론 영상 생성이 너무 쉬워진 만큼 딥페이크 같은 윤리적 문제에 대한 주의도 필요하겠지만, 디지털 창의성을 폭발시킬 기폭제가 될 것은 분명해 보입니다.
#GLM47 #Zai #오픈소스AI #코딩AI #SWEbench #가성비AI #중국AI
중국 Z.ai, 오픈소스 코딩 끝판왕 'GLM-4.7' 출시!
<SWE-bench 73.8%로 중국 최초 70%, 서구권 최신 모델들과 어깨 나란히 >by.VQZ
ⓒ Z.ai
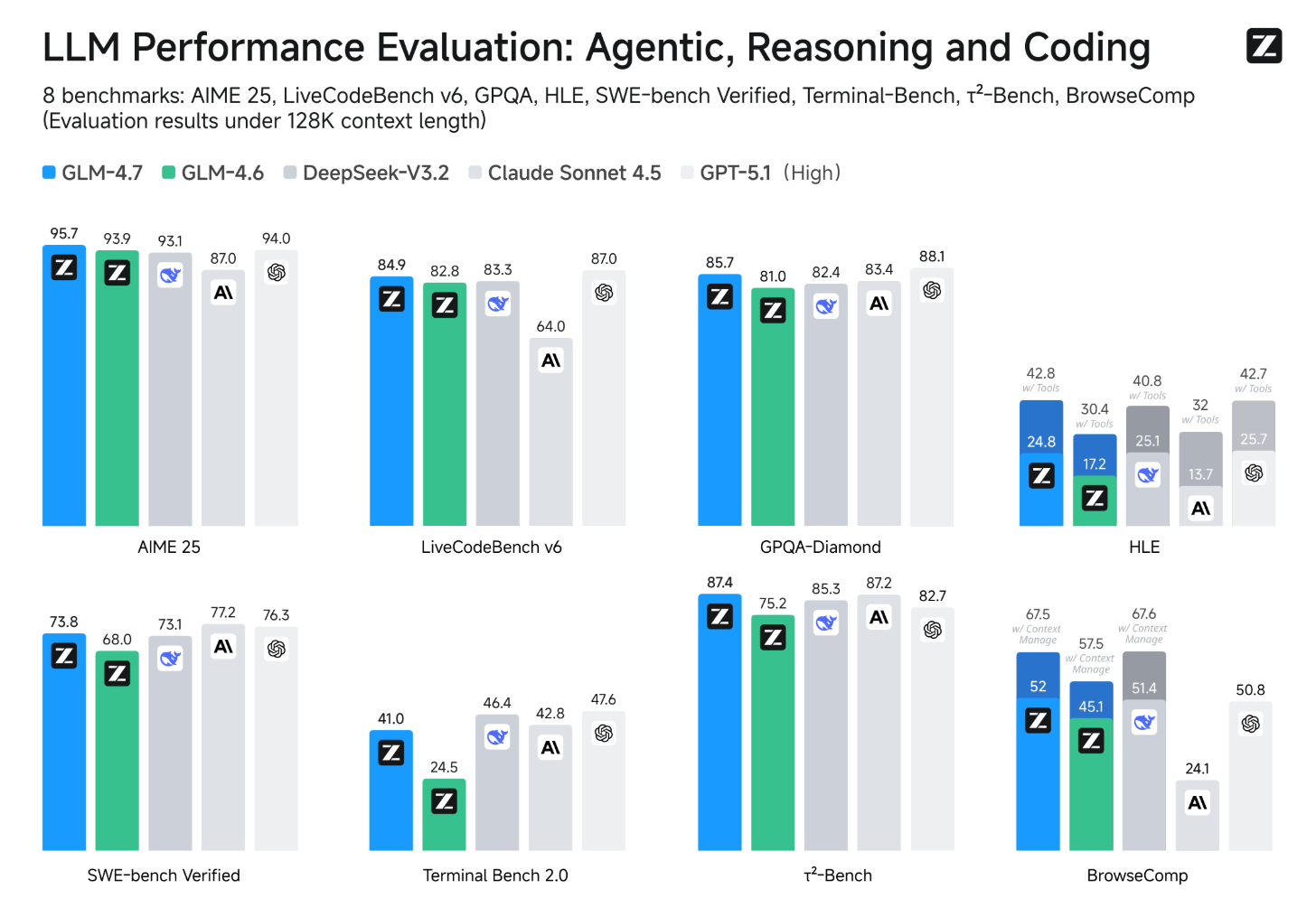
알리바바의 지원을 받는 중국의 유망 AI 스타트업 Z.ai가 오픈소스 코딩 모델의 새로운 기준이 될 'GLM-4.7'을 전격 공개했습니다. 홍콩 증시 상장을 앞두고 발표된 이번 모델은 실제 코딩 능력을 측정하는 SWE-bench에서 73.8%라는 놀라운 점수를 기록했는데요. 이는 중국 AI 연구소 중 최초로 70% 벽을 넘은 것이며, DeepSeek이나 Kimi 같은 쟁쟁한 경쟁 모델들을 뛰어넘는 성적입니다.
GLM-4.7의 가장 큰 특징은 '생각하고 행동하는' 능력입니다. 단순히 코드를 짜는 것에 그치지 않고, 복잡한 작업을 수행하기 전에 미리 추론 과정을 거치는 'Interleaved Thinking' 기능을 강화했어요. 특히 멀티턴 대화에서도 이전의 사고 과정을 유지하는 'Preserved Thinking' 덕분에, 긴 호흡이 필요한 프로젝트나 복잡한 디버깅 세션에서도 일관성 있는 결과를 내놓습니다. 여기에 UI 디자인 능력까지 좋아져서, 더 현대적이고 깔끔한 웹페이지나 슬라이드를 뚝딱 만들어낼 수 있답니다.
더 반가운 소식은 이 모델의 가중치가 Hugging Face에 오픈소스로 공개되었다는 점이에요. 덕분에 누구나 로컬 환경에서 실행하거나 Claude Code 같은 코딩 에이전트에 연결해 사용할 수 있습니다. 성능은 최상급이지만 비용은 타 모델의 7분의 1 수준에 불과해 가성비까지 완벽하게 잡았죠. 2026년에는 중국의 오픈소스 모델이 서구권의 기술 리더들을 완전히 따라잡는 해가 될지도 모르겠네요!
#AI #Alibaba #Qwen #LayeredImage #이미지AI #편집AI
알리바바 Qwen ‘레이어드 이미지 생성’ 공개
<배경·인물·소품을 따로 생성… 포토샵식 AI 편집 시대 열린다> by.D-Caf
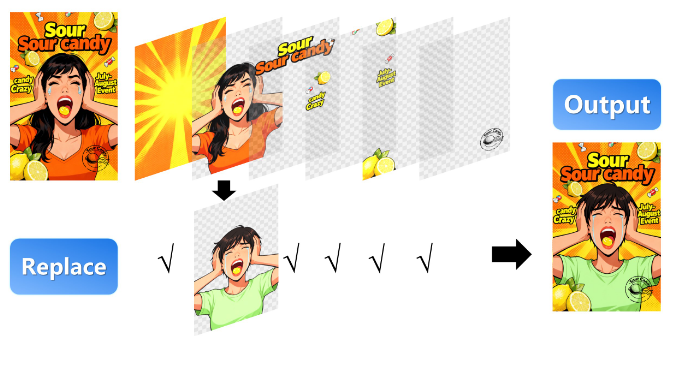
알리바바의 Qwen 팀이 Layered Image Generation 기능을 공개했어요. 한 장의 이미지를 통째로 만들어주는 방식이 아니라 배경·인물·소품을 레이어처럼 분리해서 생성하는 새로운 이미지 AI입니다.
기존 이미지 생성 AI는 결과물이 마음에 들지 않으면 처음부터 다시 만들어야 했죠. 하지만 Qwen의 레이어드 방식은 다릅니다. 배경만 바꾸거나, 인물 포즈만 수정하거나, 소품 하나만 교체하는 식으로 부분 수정이 가능해졌어요. 포토샵에서 레이어 켜고 끄듯, AI 이미지도 구조적으로 다룰 수 있게 된 셈입니다.
이 기능은 특히 브랜드·마케팅·콘텐츠 제작에 강점을 보입니다. 예를 들어 모델 사진은 그대로 두고 배경만 계절별로 바꾸거나, 제품 컷에서 제품은 유지한 채 소품과 분위기만 바꾸는 작업이 훨씬 쉬워져요. “느낌만 바꿔서 몇 버전 더 만들어줘” 같은 요청이 자연스럽게 처리됩니다.
Qwen은 이 레이어 구조 덕분에 일관성 문제도 크게 줄었다고 설명했어요. 인물 얼굴이 바뀌거나 제품 형태가 흔들리는 현상이 줄어들고 수정 작업을 반복해도 전체 구도가 안정적으로 유지됩니다. 단순 생성 모델을 넘어 편집 친화형 이미지 AI로 방향을 확실히 잡은 모습이에요.
이번 업데이트는 이미지 AI의 흐름이 “한 번 뽑고 끝”에서 “만들고, 고치고, 다듬는 과정”으로 이동하고 있다는 신호로 보입니다. 이제 AI 이미지도 점점 디자이너의 작업 방식에 가까워지고 있네요. 곧 “AI로 만든 이미지라서 고치기 어렵다”는 말은 사라질지도 모르겠습니다 😉