님, 안녕하세요!
AI 트렌드 Bold Flick의 마흔 두번째 소식이에요!
이번 주는 마치 영화 속 장면 같은 AI 기술이 현실이 된 이야기들로 가득해요.
구글은 이제 스마트폰 카메라로 세상을 보며 AI와 실시간 대화를 시도하고 아마존은 여러분의 목소리를 이해하고 ‘응답’까지 해주는 진짜 음성 AI를 만들었죠.
게다가 Meta는 텍스트와 이미지를 동시에 똑똑하게 해석하는 LLaMA 4를 공개하면서, "AI랑 진짜 소통하는 시대"가 한 발짝 더 가까워졌답니다.
그럼, 오늘도 재밌고 놀라운 AI 이야기 함께 만나볼까요? 🚀
|
|
|
#Google #제미나이Live #프로젝트아스트라 #실시간AI #Project Astra
구글, 제미나이 Live의 실시간 영상 기능 확장!
|
|
|
<프로젝트 아스트라(Project Astra) 다국어 대화와 화면 공유로 AI와 소통> by.VQZ
|
|
|
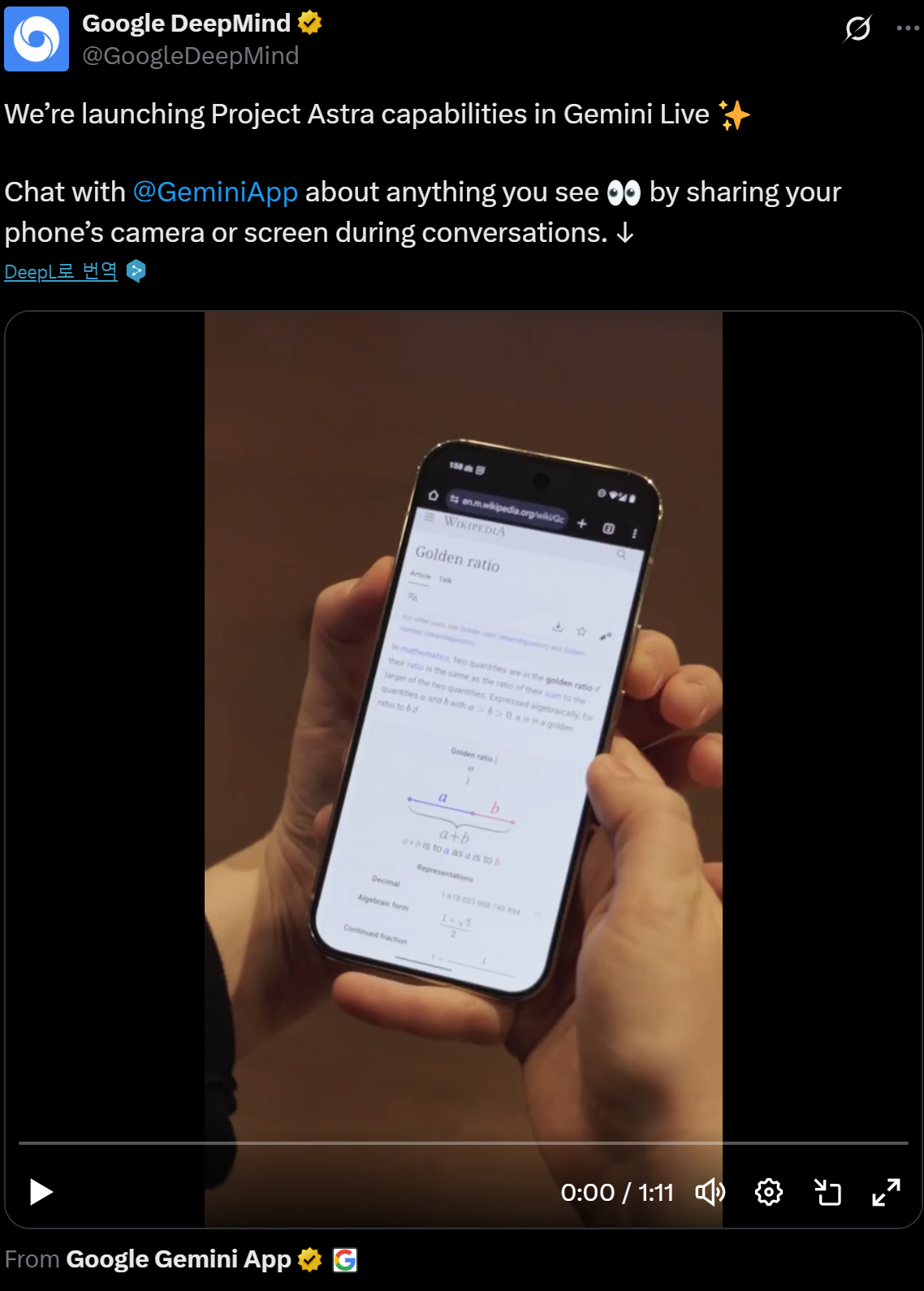
구글이 제미나이 Live의 ‘프로젝트 아스트라’ 기능을 확장해, 이제 더 많은 안드로이드 디바이스에서 실시간 영상 AI 기능을 제공한다고 발표했어요. 이번 업데이트로 사용자는 스마트폰 카메라나 화면 공유를 통해 보거나 듣는 것에 대해 제미나이 Live와 다국어로 대화할 수 있게 되었고, 이는 기존 구글 렌즈 스냅샷 기능보다 한 단계 진화한 모습입니다. |
|
|
현재 이 기능은 픽셀 9와 삼성 갤럭시 S25 기기에서 사용할 수 있으며, 삼성은 자사 플래그십 사용자에게 별도의 추가 비용 없이 제공한다고 해요. 초기 테스트 결과, 이 ‘실시간’ 기능은 데모에서 보여졌던 연속적인 영상 분석보다는 개선된 구글 렌즈와 유사하게 작동하는 것으로 나타났어요. 즉, 한 장의 스냅샷처럼 순간적으로 정보를 처리하는 방식으로 동작하지만, 앞으로 더 발전하여 지속적으로 영상 전체를 분석하는 기능으로 개선될 여지가 충분하다고 합니다.
프로젝트 아스트라는 지난 5월 Google I/O에서 처음 공개되었고, Advanced 구독자 대상으로 지난 달 첫 공개된 이후 점차 확대되고 있어요. 이처럼 AI가 주변 세계를 실시간으로 인식하고 이해하는 기술이 발전함에 따라, 스마트 글래스나 웨어러블 기기와의 연계가 궁극적인 목표로 다가오고 있습니다. |
|
|
#아마존노바소닉 #음성AI #AWS베드락 #아마존 #nova sonic
아마존 노바 소닉! AI 음성 응용이 가능한 모델 출시!
|
|
|
<음성 이해와 생성의 통합으로 자연스러운 대화와 업무 자동화 실현> by.VQZ
|
|
|
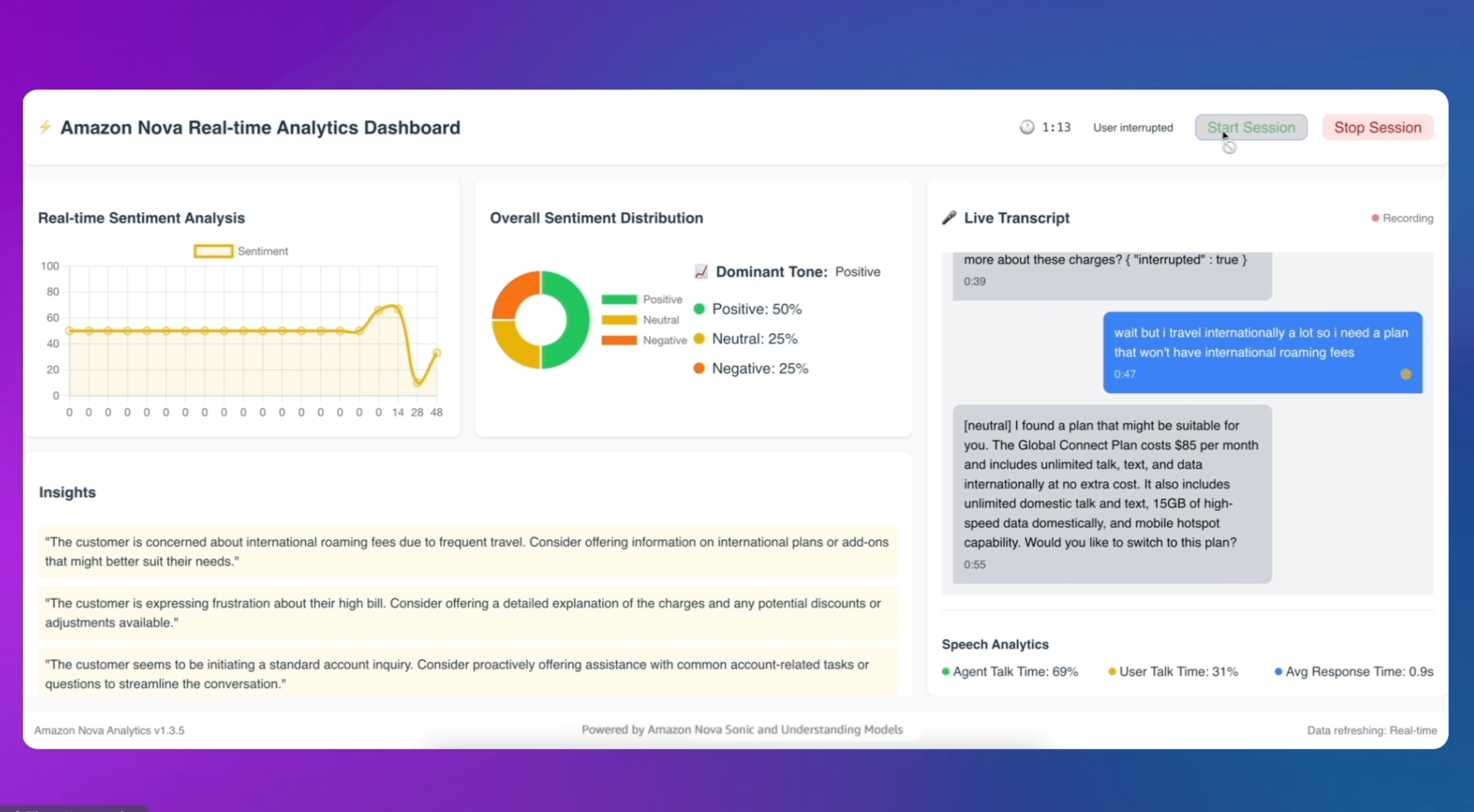
아마존이 새로운 AI 모델, 노바 소닉(Nova Sonic)을 출시했어요. 해당 모델은 음성 이해와 음성 생성을 하나로 통합해, 고객 서비스나 예약, IT 작업 등 다양한 업무를 자동으로 처리할 수 있는 AI 에이전트를 구축하는 데 큰 도움을 줍니다.
노바 소닉은 Amazon Bedrock을 통해 제공되며, 양방향 스트리밍 API를 활용해 사용자의 음성이 끝난 직후 거의 실시간으로 응답을 생성해요. 전통적으로 음성 애플리케이션은 음성 인식, 언어 모델, 텍스트-음성 변환 등 여러 모델을 결합해 사용해야 했지만, 노바 소닉은 이 모든 과정을 하나의 통합된 아키텍처로 해결해 보다 자연스럽고 정확한 대화를 구현합니다.
특히, 노바 소닉은 음성 입력을 텍스트로 변환한 후 관련 도구를 호출해 필요한 정보를 찾아주고, 동시에 자연스러운 음성을 생성해 회신합니다. 미국식과 영국식 등 다양한 영어 음성과 남성 및 여성 목소리를 지원해, 사용자에게 풍부한 선택지를 제공합니다. 평균 응답 지연 시간은 1.09초로, 경쟁 모델보다 더 빠른 속도를 자랑하며 비용면에서도 최대 80% 이상 절감되는 굉장한 성능을 보여줍니다.
실제로, ASAPP, EF와 같은 교육 및 고객 서비스 기업, 그리고 스포츠 데이터 제공업체인 Stats Perform 등이 노바 소닉을 활용해 고객 만족도와 업무 효율성을 크게 향상시키고 있어요. 아마존은 또한 AWS AI Service Cards를 통해 안전하고 책임감 있는 AI 사용 가이드를 제공, 투명성을 높이고 있습니다.
음성 인식과 생성이 하나로 결합된 노바 소닉이 앞으로 우리의 일상과 업무 환경에 가져올 변화를 여러분은 어떻게 기대하시나요?
|
|
|
#AI #Meta #LLaMA4 #멀티모달AI #AI모델
메타 LLaMA 4로 AI 판도 흔든다!
|
|
|
<이젠 글도 이미지도 동시에 이해하는 초능력자 등장!> by.D-Caf
|
|
|
요즘 AI가 점점 사람처럼 말도 잘하고 그림도 척척 그리죠? 그런데 메타가 이번에 공개한 LLaMA 4는 그걸 넘어서 말도 알아듣고 이미지도 동시에 이해하는 초능력 같은 능력을 갖춘 모델이에요.
이제 “이게 뭐야?”라고 사진 하나 던지면 AI가 말로 설명해주고 거기서 파생된 질문까지 척척 대답하는 시대가 진짜로 왔다는 거죠! |
|
|
LLaMA 4, 진짜 뭐가 그렇게 대단한가요?
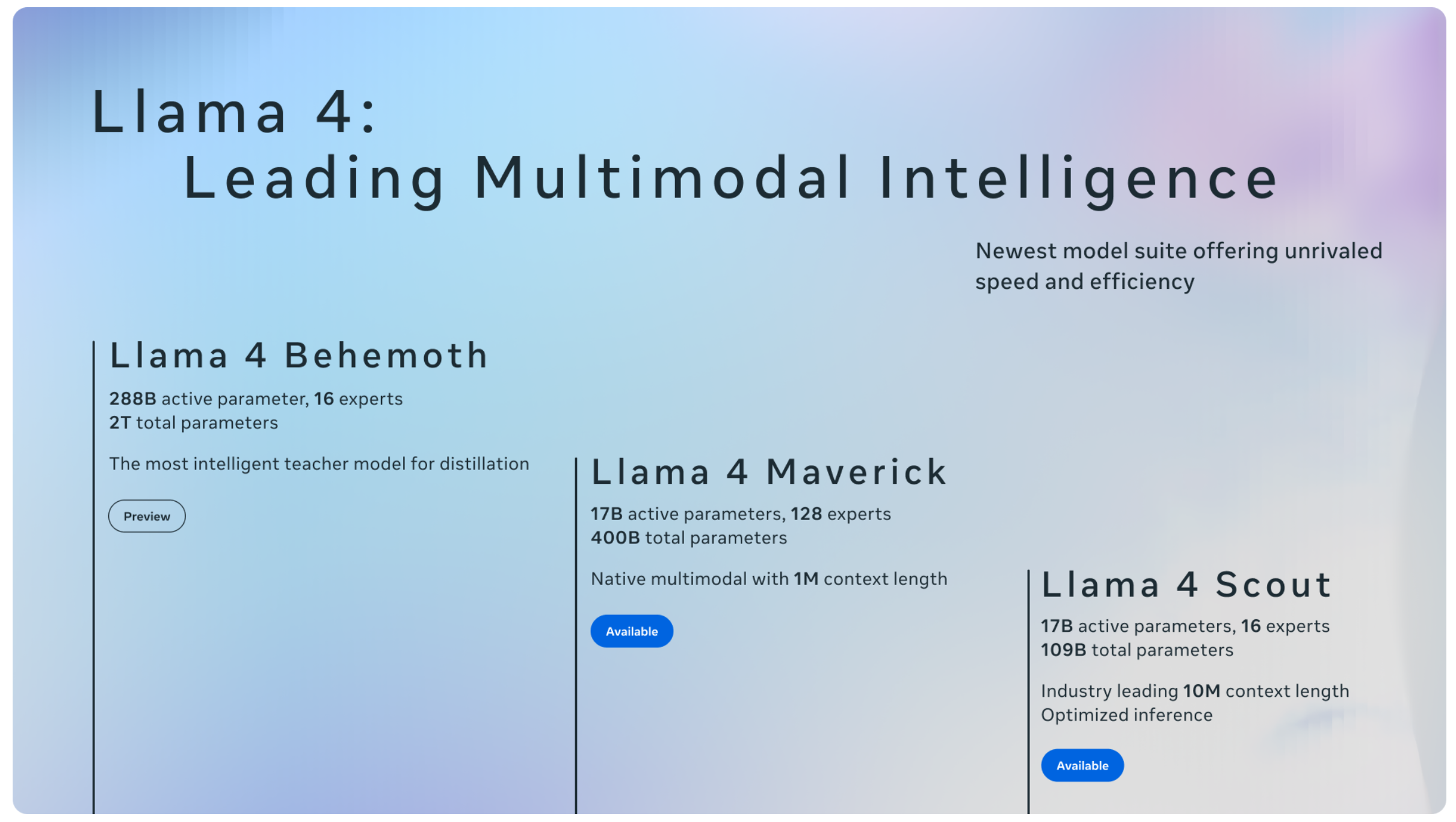
Meta가 이번에 공개한 LLaMA 4는 멀티모달(multimodal) AI예요.
텍스트와 이미지를 동시에 이해하고 연관된 개념을 추론할 수 있죠.
예를 들어 “이 이미지는 무슨 상황일까요?”라고 물어보면 단순히 ‘사람 있음’ 같은 답이 아니라, 감정, 배경, 의도까지 파악해서 알려준다고 해요.
그리고 놀라운 건 아직 “베타 버전”이라는 사실! 정식 버전도 아닌데도 벌써 이 정도 퀄리티라니… 풀파워 버전은 얼마나 대단할지 상상도 안 되네요. |
|
|
LLaMA Chat도 함께 업그레이드!
이번에 함께 발표된 LLaMA Chat도 완전 물건이에요.
이건 LLaMA 4를 기반으로 한 채팅형 인터페이스인데요,
기존 챗봇보다 훨씬 더 자연스럽고 깊이 있는 대화를 가능하게 했어요.
예를 들어 하나의 질문에 대해 A, B, C 각 관점으로 분석해주는 ‘멀티 앵글 응답’이나 이전 맥락을 잊지 않고 계속 이어가는 ‘장기 기억 대화’가 가능해졌대요. 말 그대로 대화가 끊기지 않는 똑똑한 친구가 생긴 거죠.
|
|
|
모두에게 열려 있어요!
Meta는 이 기술을 단순히 자랑만 하고 끝내지 않았어요.
개발자와 연구자들을 위해 LLaMA 4를 오픈소스 형태로 공개했어요!
이미 Hugging Face나 PyTorch, Docker 등 여러 플랫폼에서 쉽게 활용할 수 있도록 지원하고 있고요 연구 용도로는 무료로 접근할 수 있다는 점도 반가운 소식이에요. |
|
|
멀티모달 AI, 진짜 세상을 바꿀까?
지금까지는 “텍스트는 텍스트끼리, 이미지는 이미지끼리” 따로 노는 AI가 많았는데
LLaMA 4 같은 모델은 그 벽을 허물고 모든 정보를 함께 해석할 수 있게 해줘요.
앞으로 AI가 사람처럼 세상을 보고, 듣고, 이해하고, 설명해주는 ‘초인류 파트너’가 될 수도 있겠죠?
Meta가 보여준 이 방향이 진짜 미래의 AI 모델 기본템이 될지 우리 함께 지켜봐요. 지금보다 더 똑똑하고 따뜻한 AI 세상 곧 열릴지도 몰라요! 🤖💬🖼️
|
|
|
오늘의 'Bold Flick'은 여기까지!
다음 뉴스레터에서는 더욱 놀랍고 흥미로운 AI 소식으로 찾아뵐게요.
언제나 Bold Flick을 사랑해주셔서 감사합니다! 💙
궁금한 점이 있거나 더 알고 싶은 주제가 있다면 언제든 말씀해 주세요.
여러분의 피드백이 저희에게 큰 힘이 된답니다!
|
|
|
|